Strings
2023-03-08
Introduction
The problem
What’s different between these data sets?
What is needed to create data2 from data1?
data1# A tibble: 12 × 3
id cond resp
<int> <chr> <chr>
1 1 cond1 yes
2 2 cond2 no
3 3 cond1 yes
4 4 cond2 yes
5 5 cond1 no
6 6 cond2 yes
7 7 cond1 yes
8 8 cond2 no
9 9 cond1 no
10 10 cond2 no
11 11 cond1 yes
12 12 cond2 yes data2# A tibble: 12 × 4
id cond resp output
<int> <chr> <chr> <glue>
1 1 1 Yes 1 had condition 1 and said "Yes"
2 2 2 No 2 had condition 2 and said "No"
3 3 1 Yes 3 had condition 1 and said "Yes"
4 4 2 Yes 4 had condition 2 and said "Yes"
5 5 1 No 5 had condition 1 and said "No"
6 6 2 Yes 6 had condition 2 and said "Yes"
7 7 1 Yes 7 had condition 1 and said "Yes"
8 8 2 No 8 had condition 2 and said "No"
9 9 1 No 9 had condition 1 and said "No"
10 10 2 No 10 had condition 2 and said "No"
11 11 1 Yes 11 had condition 1 and said "Yes"
12 12 2 Yes 12 had condition 2 and said "Yes"Set-up
Mental model
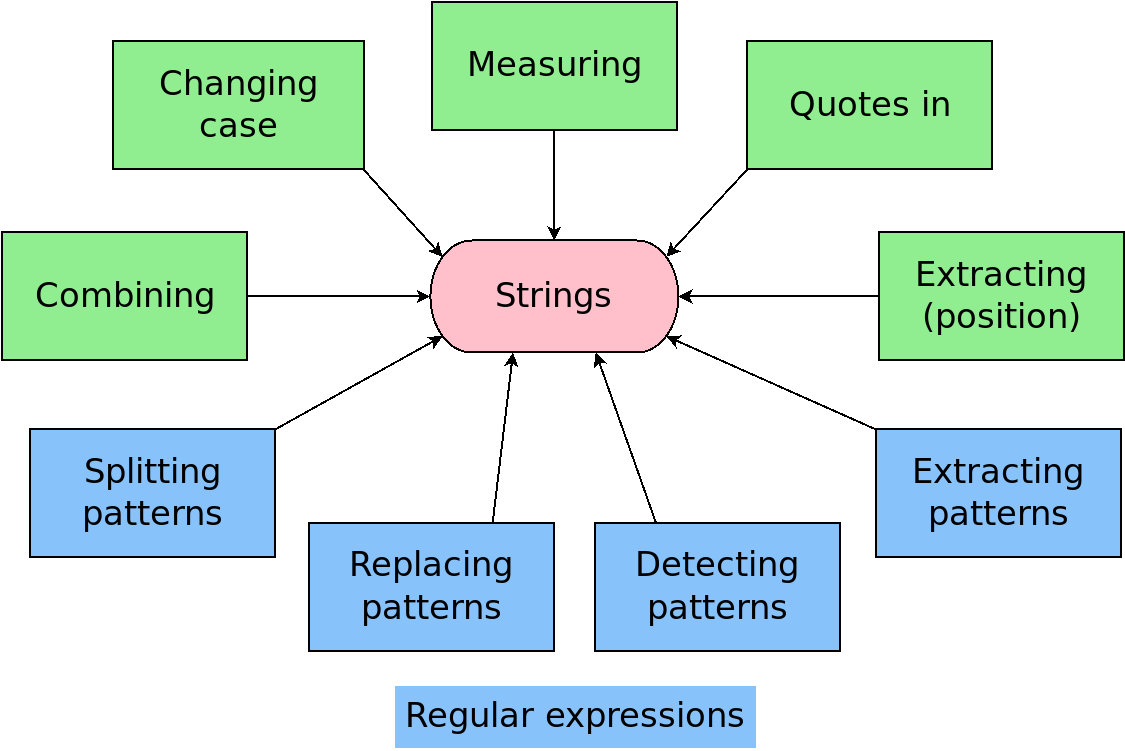
Character string basics
Useful character vectors
letters [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s"
[20] "t" "u" "v" "w" "x" "y" "z"LETTERS [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S"
[20] "T" "U" "V" "W" "X" "Y" "Z"month.name [1] "January" "February" "March" "April" "May" "June"
[7] "July" "August" "September" "October" "November" "December" month.abb [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"Quotes
Create strings with either single quotes or double quotes
(string1 <- "This is a string")[1] "This is a string"writeLines(string1)This is a string(string2 <- 'So is this.')[1] "So is this."writeLines(string2)So is this.Quotes
Including quotes in strings
(string3 <- 'If I want to include a "double quote" inside a string, I use single quotes')[1] "If I want to include a \"double quote\" inside a string, I use single quotes"writeLines(string3)If I want to include a "double quote" inside a string, I use single quotes(string4 <- "And 'vice versa'")[1] "And 'vice versa'"writeLines(string4)And 'vice versa'Escaping quotes
Or use \ to “escape” it
Escaping quotes
Because \ escapes, you can’t just wrap it in quotes
If you want an actual backslash printed, you need two \\
backslash <- "\\"
writeLines(backslash)\
Working with strings
Strings with {stringr}


String length
Return number of characters in a string with stringr::str_length()
(r4ds_string <- c("a", "R for data science", NA))[1] "a" "R for data science" NA str_length(r4ds_string) # nchar() in base R[1] 1 18 NA# This differs from length...
length(r4ds_string)[1] 3Extracting strings
Extract parts of a string based on position with stringr::str_sub()
Extracting strings
Useful when you don’t have delimiters. But use delimiters!
penguins |>
mutate(species = str_sub(species, 1, 1),
island = str_sub(island, 1, 3),
year = str_sub(year, -2, -1), .keep = "used")# A tibble: 344 × 3
species island year
<chr> <chr> <chr>
1 A Tor 07
2 A Tor 07
3 A Tor 07
4 A Tor 07
5 A Tor 07
6 A Tor 07
7 A Tor 07
8 A Tor 07
9 A Tor 07
10 A Tor 07
# … with 334 more rowsExtracting strings
Also can substitute characters based on position
Changing case
Control capitalization with stringr::str_to_lower() and stringr::str_to_upper()
(y <- "hello, World")[1] "hello, World"str_to_lower(y) # tolower() in base R[1] "hello, world"str_to_upper(y) # toupper() in base R[1] "HELLO, WORLD"Changing case
Plus super useful stringr::str_to_title() and stringr::str_to_sentence()
Changing case
Useful for column names
names(iris)[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species" str_to_lower(names(iris))[1] "sepal.length" "sepal.width" "petal.length" "petal.width" "species" Changing case
Or to change case of column entries
penguins |>
mutate(sex_upper = str_to_sentence(sex), .keep = "used")# A tibble: 344 × 2
sex sex_upper
<fct> <chr>
1 male Male
2 female Female
3 female Female
4 <NA> <NA>
5 female Female
6 male Male
7 female Female
8 male Male
9 <NA> <NA>
10 <NA> <NA>
# … with 334 more rowsBut notice what happened to data type
Combining strings
Combining strings
Combine multiple strings into a single string with stringr::str_c():
Collapsing strings
Collapse a vector of strings into a single string with collapse argument
How is this different from using sep argument?
str_c("x", "y", "z", sep = ", ")[1] "x, y, z"Collapsing strings
When would this be useful?
Combining strings with output
Pasting character vectors with base R paste()
name <- "Fred"
age <- 50
paste("My name is", name, ", and my age next year is", age + 1, ".")[1] "My name is Fred , and my age next year is 51 ."paste0("My name is", name, ", and my age next year is", age + 1, ".")[1] "My name isFred, and my age next year is51."paste0("My name is ", name, ", and my age next year is ", age + 1, ".")[1] "My name is Fred, and my age next year is 51."paste("My name is ", name, ", and my age next year is ", age + 1, ".", sep = "")[1] "My name is Fred, and my age next year is 51."Combining strings with output
Gluing character vectors with stringr::str_glue()
Combining strings with output
Apply to each row of a data frame
penguins |>
mutate(full_island = str_glue("{island} Island")) |>
arrange(bill_length_mm) |>
select(species, island, full_island)# A tibble: 344 × 3
species island full_island
<fct> <fct> <glue>
1 Adelie Dream Dream Island
2 Adelie Dream Dream Island
3 Adelie Torgersen Torgersen Island
4 Adelie Dream Dream Island
5 Adelie Torgersen Torgersen Island
6 Adelie Torgersen Torgersen Island
7 Adelie Biscoe Biscoe Island
8 Adelie Torgersen Torgersen Island
9 Adelie Torgersen Torgersen Island
10 Adelie Biscoe Biscoe Island
# … with 334 more rowsCheatsheet
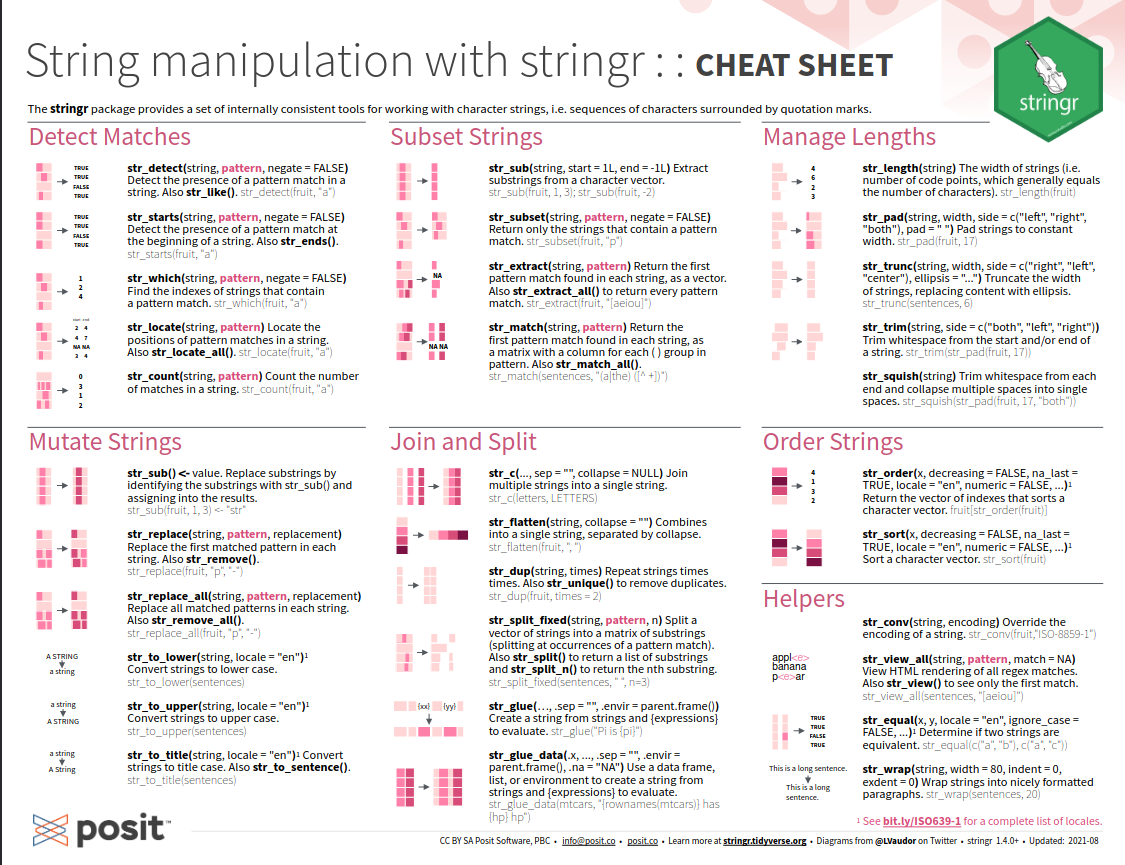
Solving the problem
data1# A tibble: 12 × 3
id cond resp
<int> <chr> <chr>
1 1 cond1 yes
2 2 cond2 no
3 3 cond1 yes
4 4 cond2 yes
5 5 cond1 no
6 6 cond2 yes
7 7 cond1 yes
8 8 cond2 no
9 9 cond1 no
10 10 cond2 no
11 11 cond1 yes
12 12 cond2 yes data2# A tibble: 12 × 4
id cond resp output
<int> <chr> <chr> <glue>
1 1 1 Yes 1 had condition 1 and said "Yes"
2 2 2 No 2 had condition 2 and said "No"
3 3 1 Yes 3 had condition 1 and said "Yes"
4 4 2 Yes 4 had condition 2 and said "Yes"
5 5 1 No 5 had condition 1 and said "No"
6 6 2 Yes 6 had condition 2 and said "Yes"
7 7 1 Yes 7 had condition 1 and said "Yes"
8 8 2 No 8 had condition 2 and said "No"
9 9 1 No 9 had condition 1 and said "No"
10 10 2 No 10 had condition 2 and said "No"
11 11 1 Yes 11 had condition 1 and said "Yes"
12 12 2 Yes 12 had condition 2 and said "Yes"