Merging columns
2023-03-01
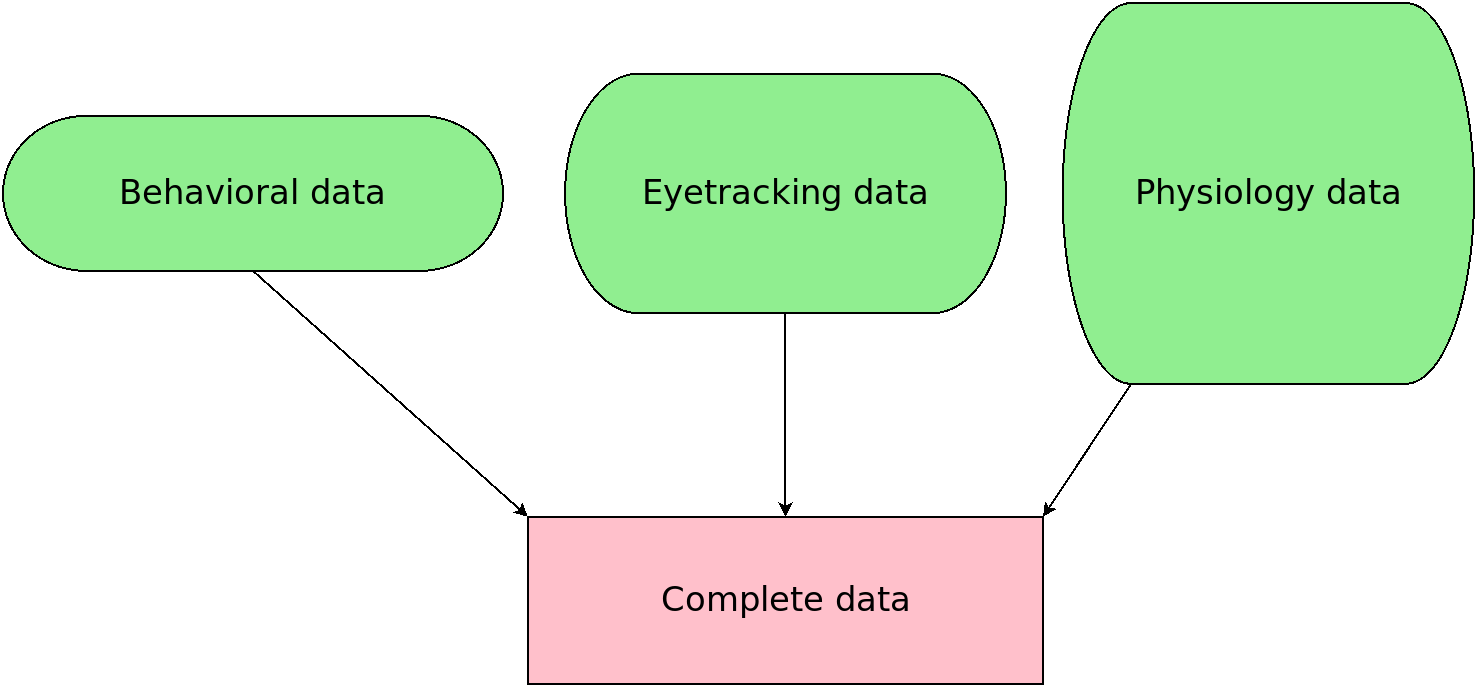
Mental model of merging
Joining with {dplyr}


Merging data
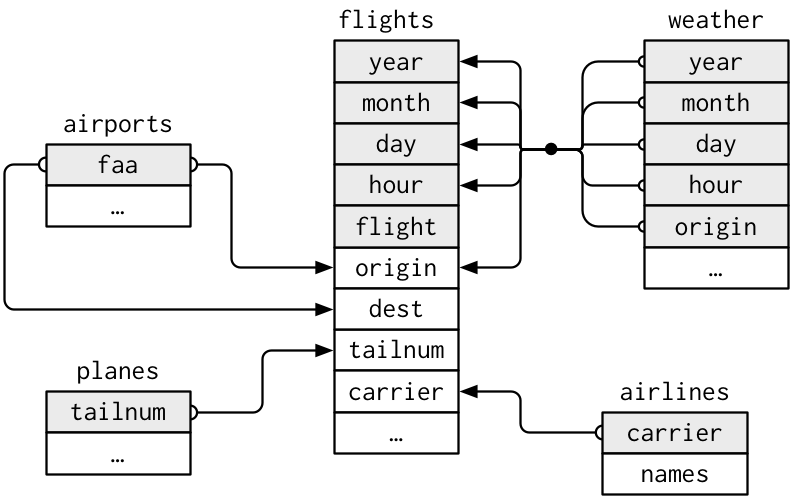
Joins
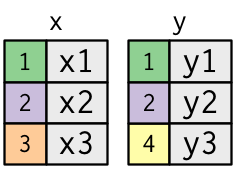
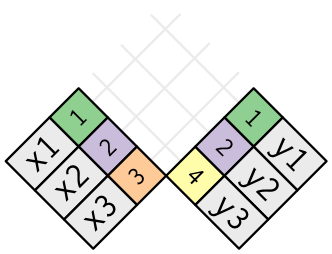
Mutating joins
Affects columns

Mutating joins
Affects columns
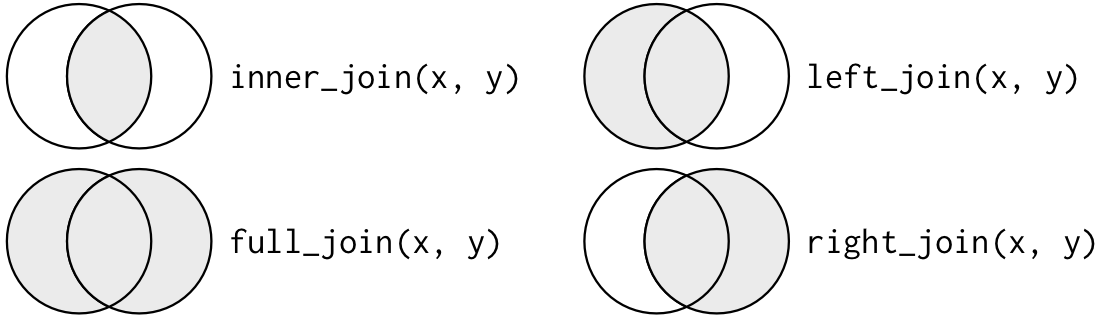
Inner joins
Keep only matching observations
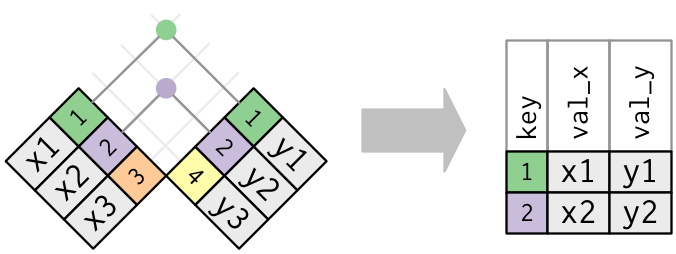

Inner joins
x# A tibble: 3 × 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2
3 3 x3 y# A tibble: 3 × 2
key val_y
<dbl> <chr>
1 1 y1
2 2 y2
3 4 y3 inner_join(x, y, by = "key")# A tibble: 2 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2 x |>
inner_join(y, by = "key")# A tibble: 2 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2 Inner joins
Warning
Only use inner joins when you want the intersection of the two data sets!
Outer joins
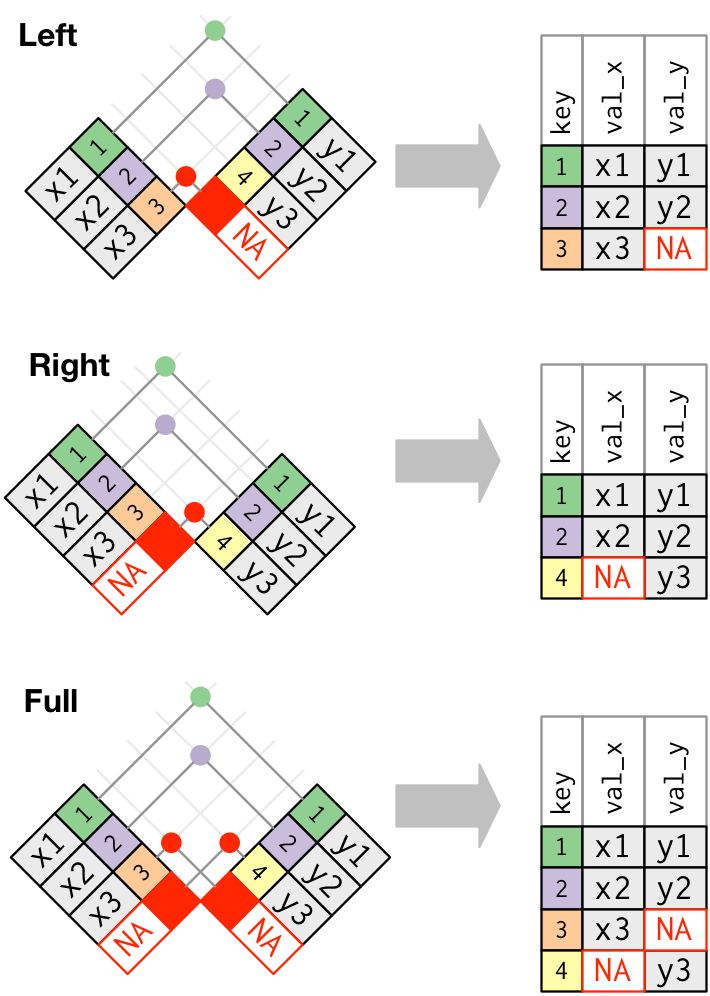
Keep observations that appear in at least one of the tables
Left
Right
Full
Left joins
Keep only left observations
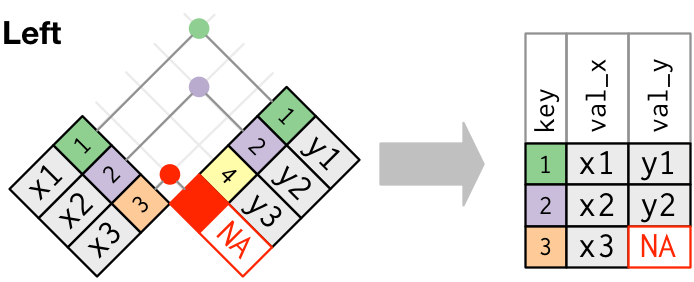
Left joins
x# A tibble: 3 × 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2
3 3 x3 y# A tibble: 3 × 2
key val_y
<dbl> <chr>
1 1 y1
2 2 y2
3 4 y3 left_join(x, y, by = "key")# A tibble: 3 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA> Right joins
Keep only right observations
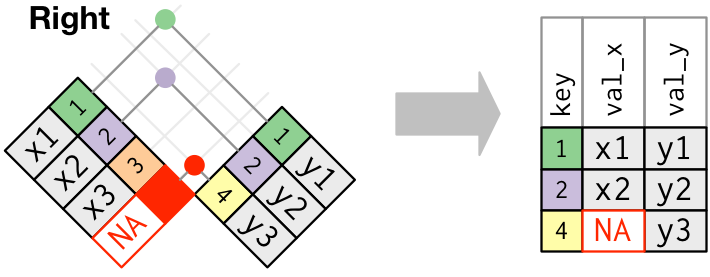

Right joins
x# A tibble: 3 × 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2
3 3 x3 y# A tibble: 3 × 2
key val_y
<dbl> <chr>
1 1 y1
2 2 y2
3 4 y3 right_join(x, y, by = "key")# A tibble: 3 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 4 <NA> y3 Full joins
Keep all observations
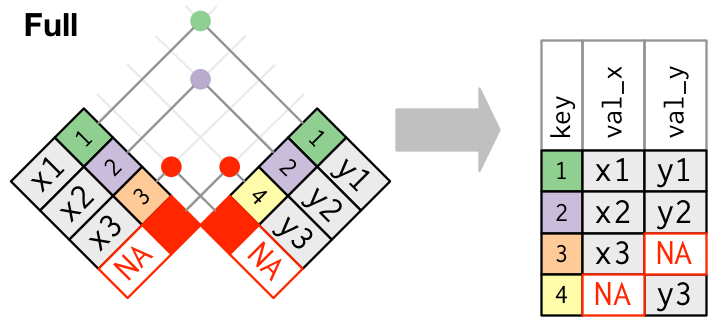
Full joins
x# A tibble: 3 × 2
key val_x
<dbl> <chr>
1 1 x1
2 2 x2
3 3 x3 y# A tibble: 3 × 2
key val_y
<dbl> <chr>
1 1 y1
2 2 y2
3 4 y3 full_join(x, y, by = "key")# A tibble: 4 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 3 x3 <NA>
4 4 <NA> y3